# --------------------------------------------------------------- # Font Settings # See: https://theme-next.org/docs/theme-settings/#Fonts-Customization # --------------------------------------------------------------- # Find fonts on Google Fonts (https://www.google.com/fonts) # All fonts set here will have the following styles: # light | light italic | normal | normal italic | bold | bold italic # Be aware that setting too much fonts will cause site running slowly # --------------------------------------------------------------- # To avoid space between header and sidebar in scheme Pisces / Gemini, Web Safe fonts are recommended for `global` (and `title`): # Arial | Tahoma | Helvetica | Times New Roman | Courier New | Verdana | Georgia | Palatino | Garamond | Comic Sans MS | Trebuchet MS # ---------------------------------------------------------------
font: enable:true
# Uri of fonts host, e.g. https://fonts.googleapis.com (Default). host:
# Font options: # `external: true` will load this font family from `host` above. # `family: Times New Roman`. Without any quotes. # `size: x.x`. Use `em` as unit. Default: 1 (16px)
# Global font settings used for all elements inside <body>. global: external:true family:NotoSerifSC size:
# Font settings for site title (.site-title). title: external:true family:NotoSerifSC size:
# Font settings for headlines (<h1> to <h6>). headings: external:true family:NotoSerifSC size:
# Font settings for posts (.post-body). posts: external:true family:NotoSerifSC size:
# Font settings for <code> and code blocks. codes: external:true family:SourceCodePro
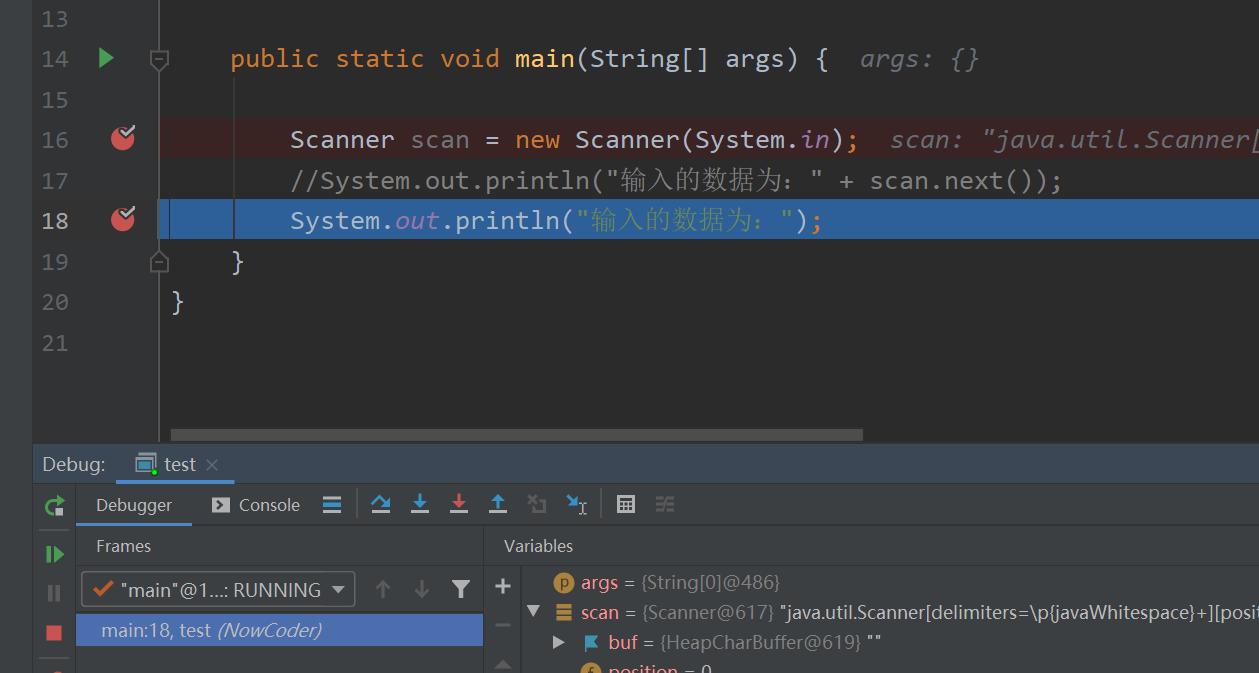
publicclasstest{ publicstaticvoidmain(String[] args){ Scanner scan = new Scanner(System.in);
// 判断是否还有输入 while(scan.hasNextInt()) { int number = scan.nextInt(); System.out.println("输入的数据为:" + number); } } }
关于牛客网和IDEA的实验结果不同的原因
以牛客OJ在线编程常见输入输出练习场中的A题目为例:
1 2 3 4 5 6 7 8 9 10 11 12 13
题目描述:计算a+b
输入描述:输入包括两个正整数a,b(1 <= a, b <= 10^9),输入数据包括多组。
输出描述: 输出a+b的结果
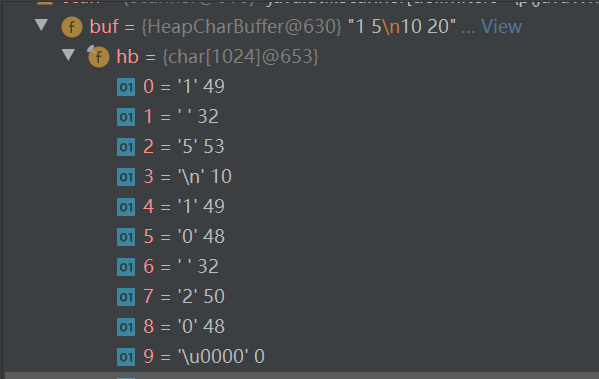
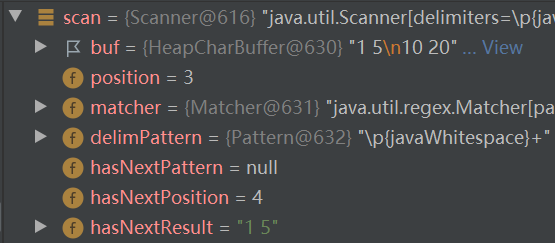
示例: 输入: 1 5 10 20 输出: 6 30
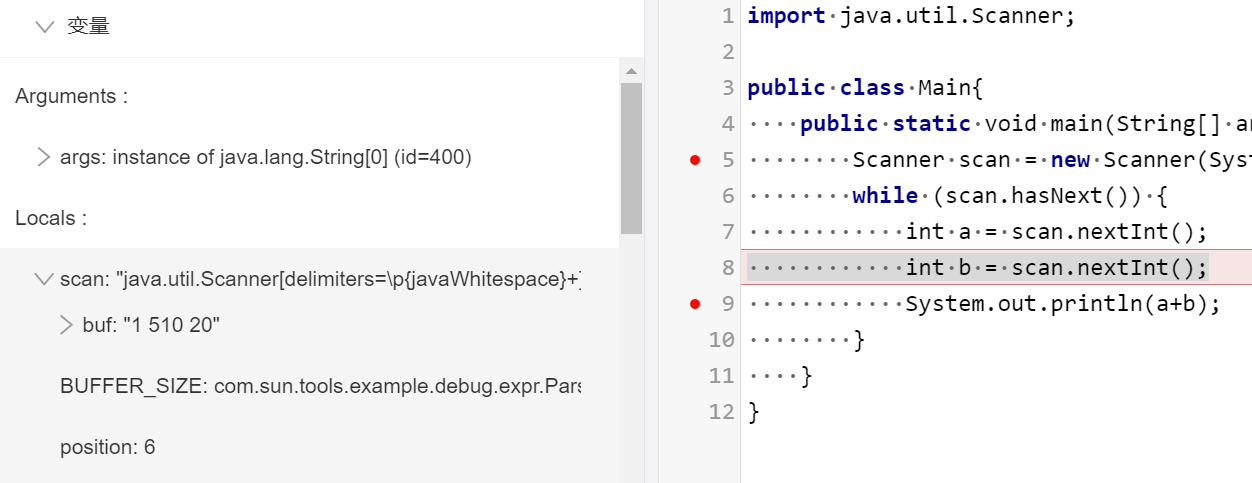
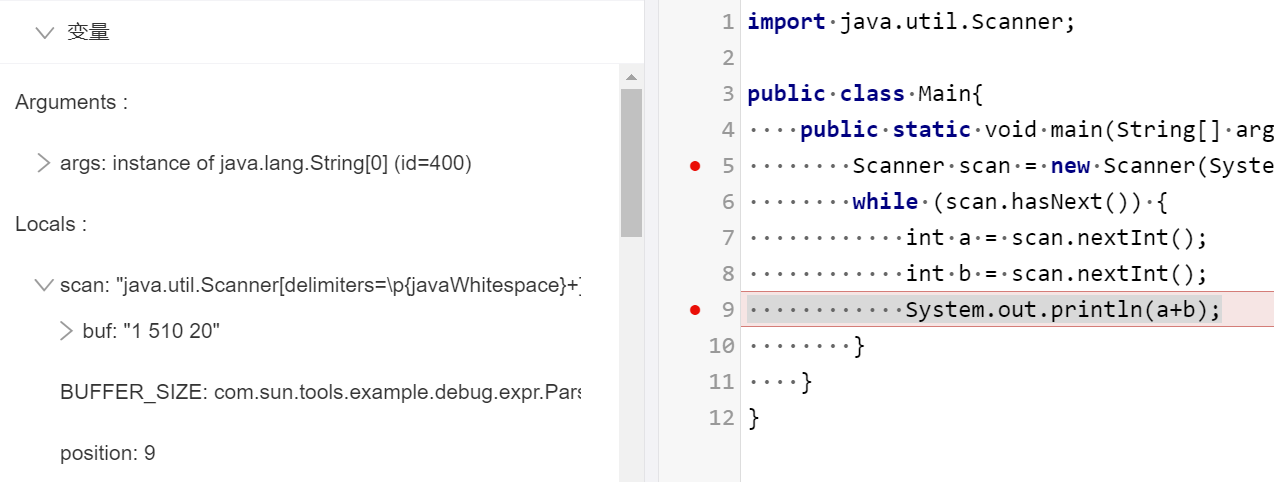
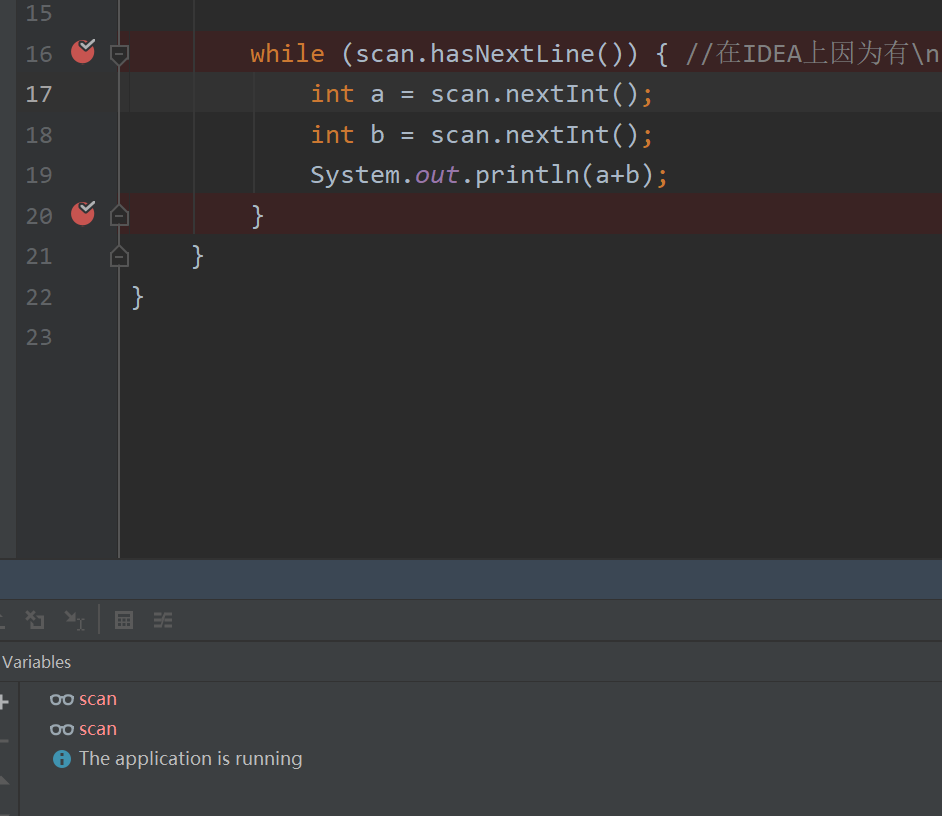
hasNext() IDEA A题
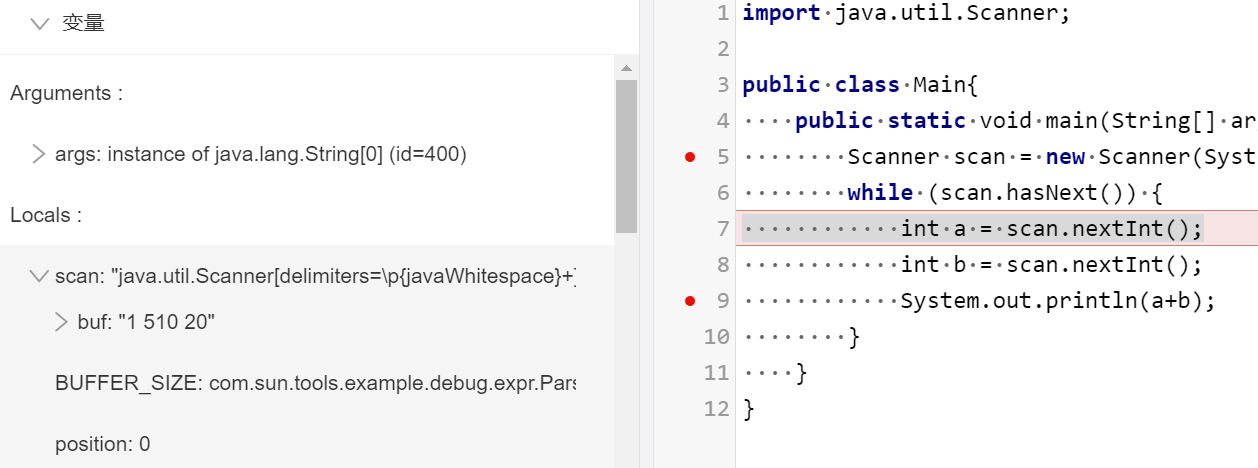
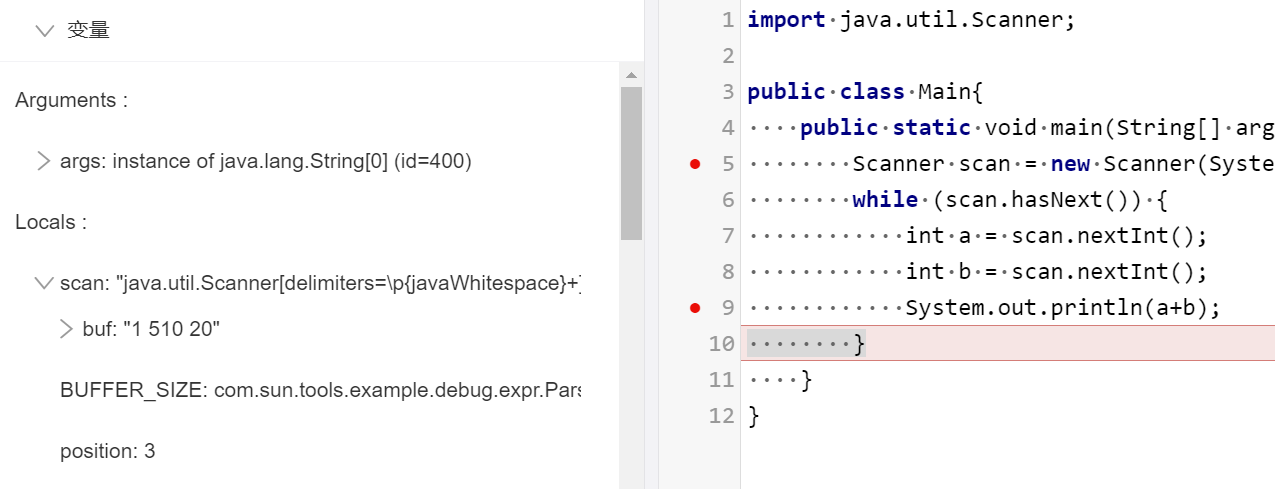
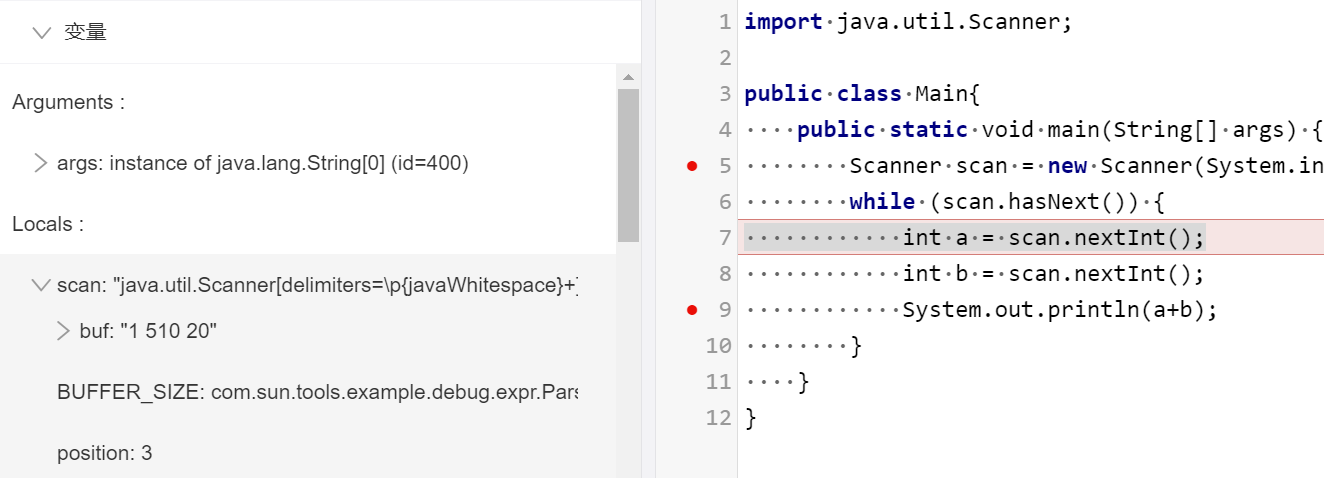
采用复制粘贴形式,将牛课上用例粘贴到IDEA控制台,用例如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
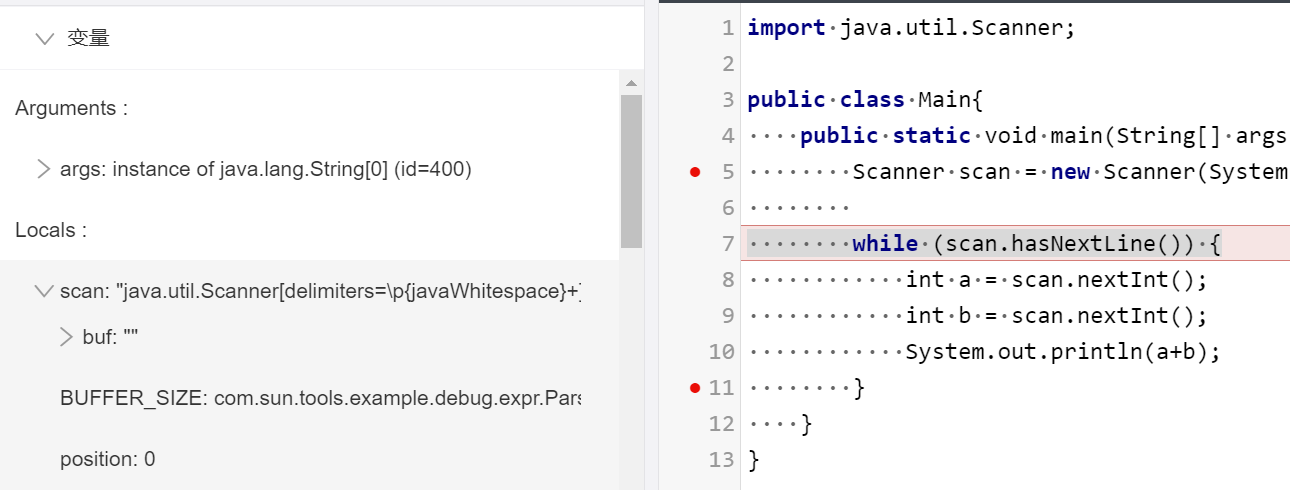
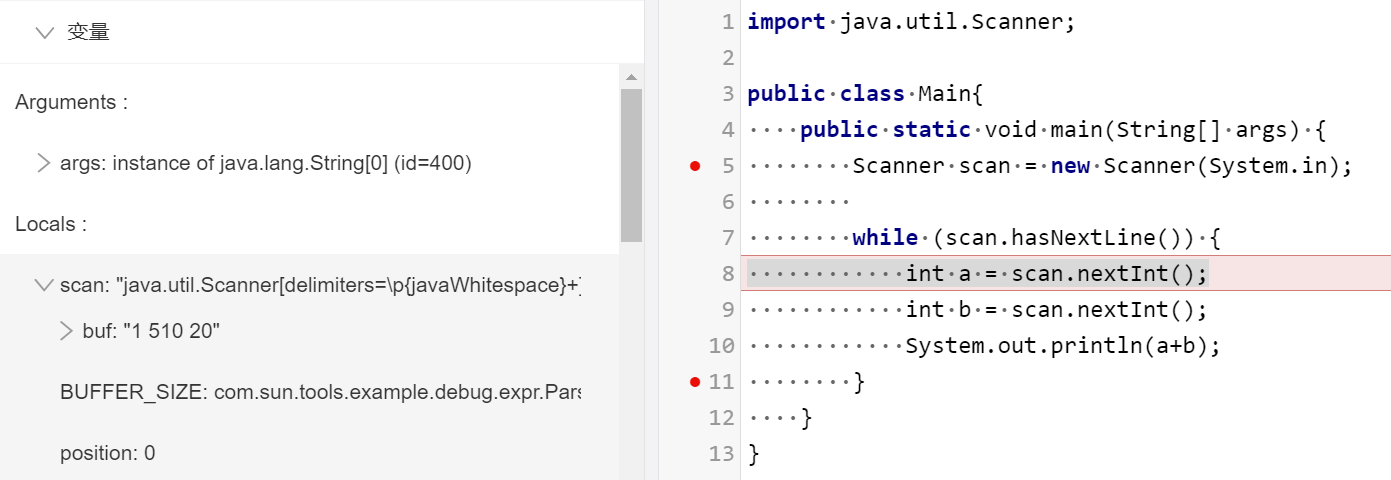
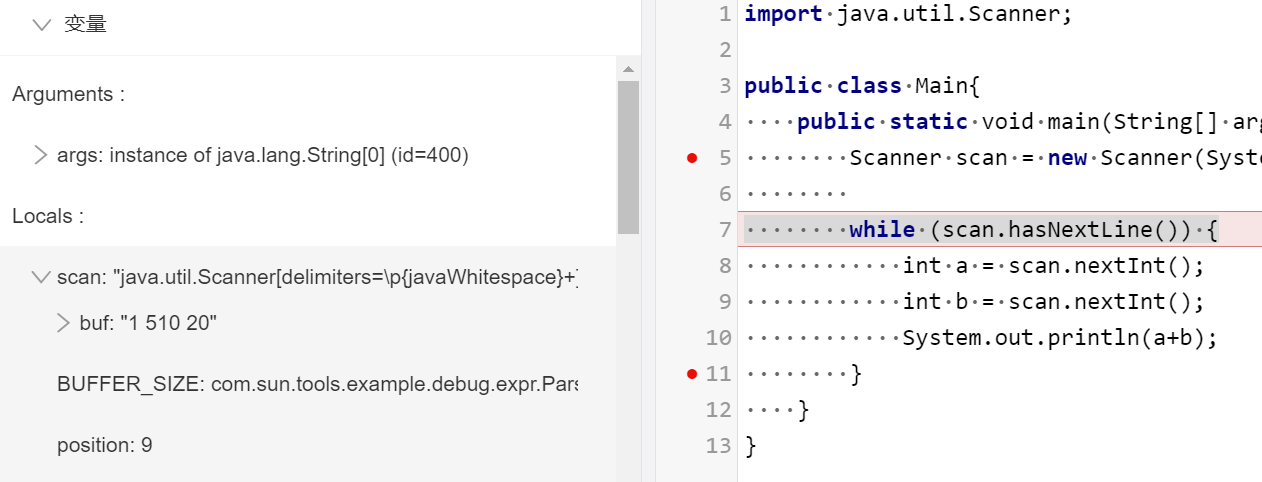
import java.util.Scanner;
publicclassMain{ publicstaticvoidmain(String[] args){ Scanner scan = new Scanner(System.in); while (scan.hasNext()) { int a = scan.nextInt(); int b = scan.nextInt(); System.out.println(a+b); } } }
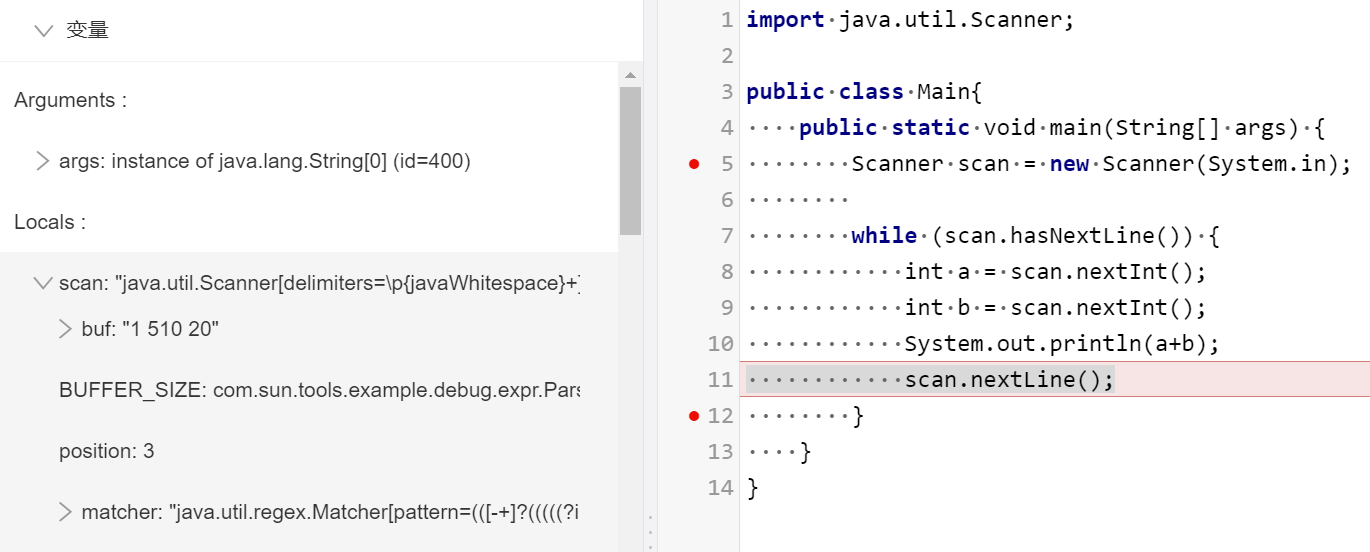
publicclassMain{ publicstaticvoidmain(String[] args){ Scanner scan = new Scanner(System.in); while (scan.hasNextLine()) { int a = scan.nextInt(); int b = scan.nextInt(); System.out.println(a+b); } } }
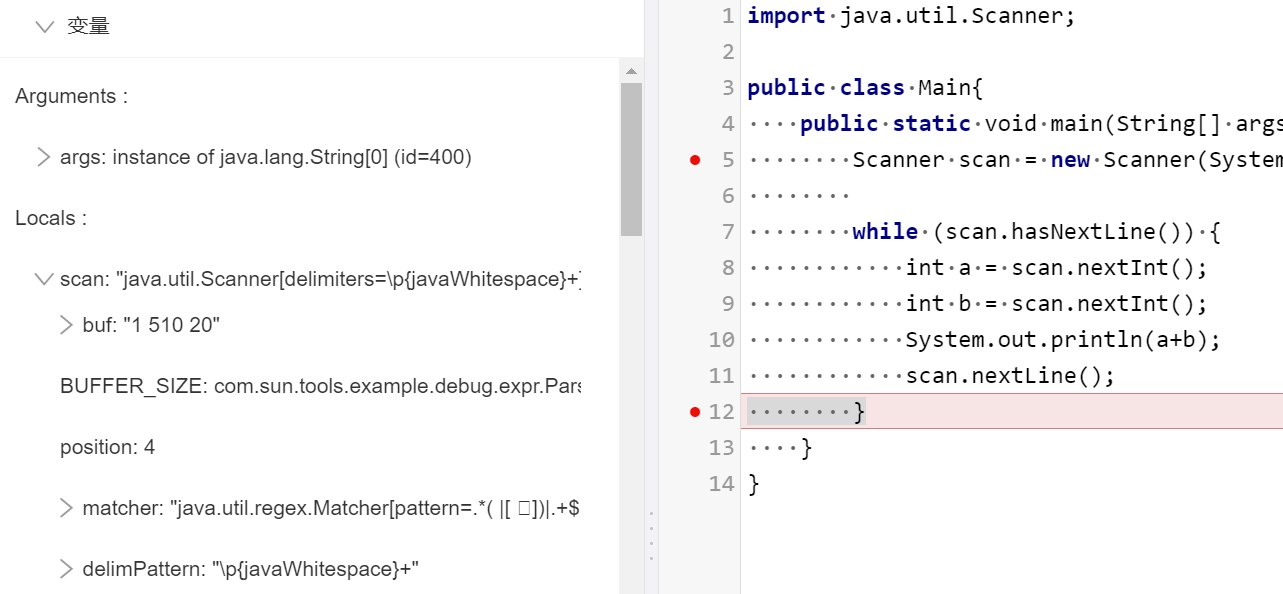
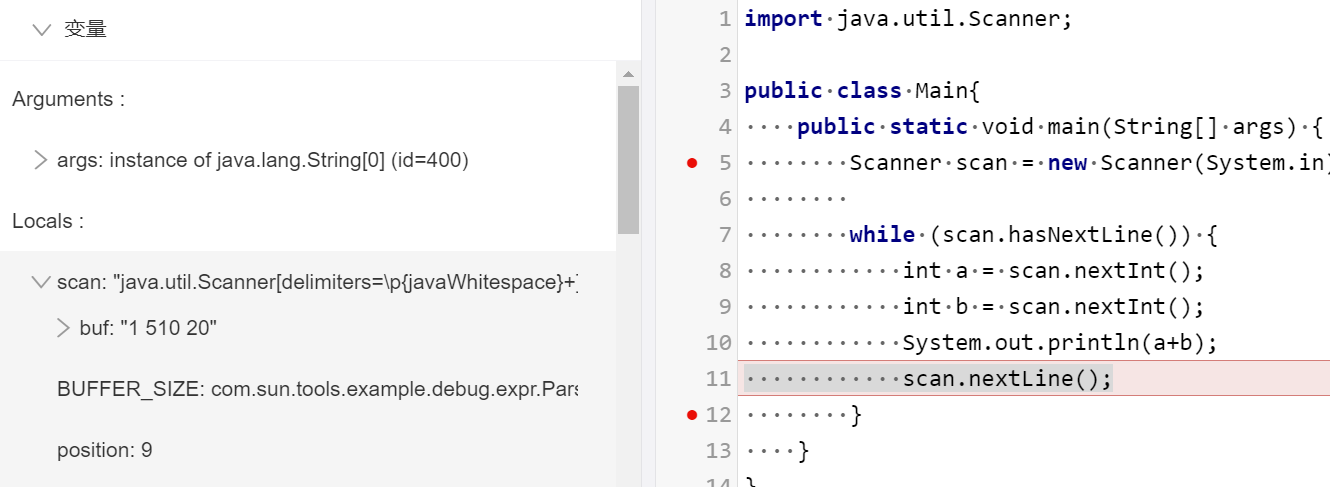
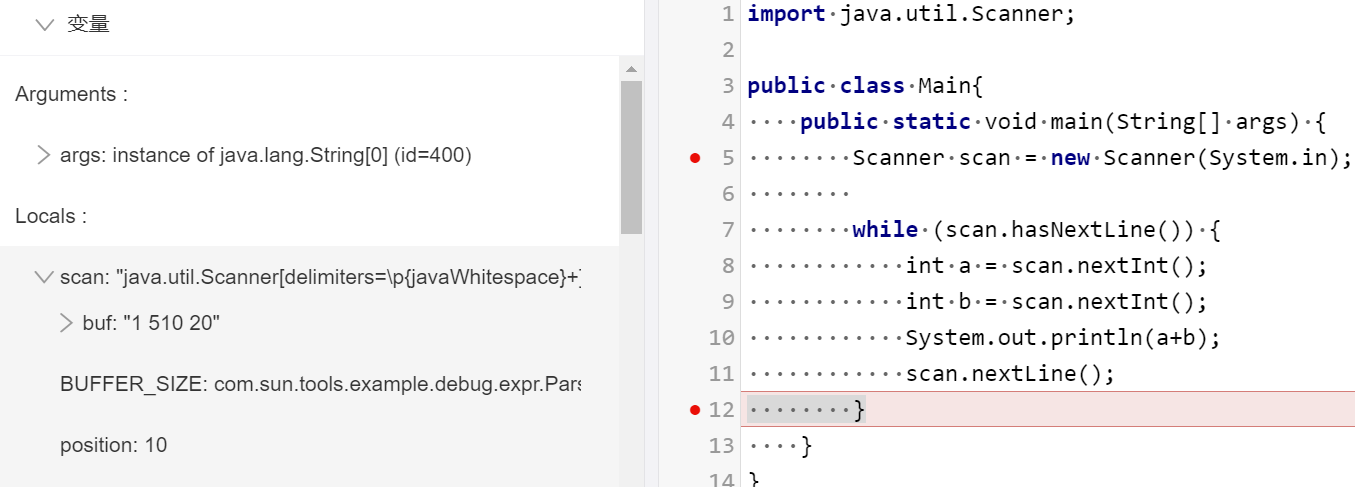
publicclassMain{ publicstaticvoidmain(String[] args){ Scanner scan = new Scanner(System.in); while (scan.hasNextLine()) { int a = scan.nextInt(); int b = scan.nextInt(); System.out.println(a+b); scan.nextLine(); } } }
publicclassG{ publicstaticvoidmain(String[] args){ Scanner scan = new Scanner(System.in);
while (scan.hasNextLine()) { //当前代码可以在牛客上通过 int result = 0; String s = scan.nextLine(); Scanner rowIn = new Scanner(s); while (rowIn.hasNextInt()) { result += rowIn.nextInt(); } System.out.println(result); } } }
publicclassG{ publicstaticvoidmain(String[] args){ Scanner scan = new Scanner(System.in);
while (scan.hasNextLine()) { //当前代码可以在牛客上通过 int result = 0; String s = scan.nextLine(); Scanner rowIn = new Scanner(s); while (rowIn.hasNextInt()) { result += rowIn.nextInt(); } System.out.println(result); } } }