Virtual Multi-view Fusion for 3D Semantic Segmentation
论文:https://arxiv.org/abs/2007.13138
会议:ECCV 2020
总结
本文在点云分割领域对多视图方法进行了研究,提出了虚拟视图的概念,避免了真实相机的局限性,提出了新的多视图方法,在scannet和s3dis上效果较多视图方法有很大的提升,但是没看到论文中对具体分割方法的介绍,可能没用到3d分割网络?该文章的代码还没有公开。
动机
体素方法缺点:
用于3D语义分割的最新技术(SOTA)方法使用3D稀疏体素卷积运算符来处理输入数据。例如,MinkowskiNet和SparseConvNet 各自将输入数据加载到稀疏3D体素网格中,并使用稀疏3D卷积提取特征。这些“placecentric”的方法旨在识别3D模式,因此对于具有独特3D形状的对象类型(例如椅子)效果很好,而对其他对象(例如墙面图片)效果不佳。它们还占用了大量内存,这限制了空间分辨率和/或批处理大小。
多视图方法缺点:
当可获得posed RGB-D图像时,尝试使用为处理摄影RGB图像而设计的2D网络预测密集的特征和/或语义标签,然后将它们聚集在可见的3D表面上,或者将特征投影到可见的表面上,并在3D中将它们进一步卷积。
尽管这些“view-centric”的方法利用了在大型RGB图像数据集上进行预训练的大规模图像处理网络,但由于在RGB-D扫描数据集中存在遮挡,光照变化和相机姿态未对准的困难,因此无法在标准3D分割基准上达到SOTA性能。在ScanNet基准测试的3D语义标签挑战赛中,基于视图的方法目前不在当前排行榜的上半部分。
贡献
本文提出了一种新的基于视图的3D语义分割方法,该方法克服了先前方法的问题。关键思想是使用从3D场景的“虚拟视图”渲染的合成图像,而不是将处理限制为由物理相机获取的原始摄影图像。
这种方法有几个优点,可以解决以前以视图为中心的方法遇到的关键问题。
- 我们可以对非自然视场的虚拟视图选择camera intrinsics,以增加在每个渲染图像中观察到的上下文。
- 我们在与场景表面的距离/角度变化较小、物体之间遮挡相对较少、表面覆盖冗余较大的位置选择虚拟视点。
- 我们渲染非真实的图像,没有依赖于视图的光照效果和背对表面的遮挡——也就是说,虚拟视图可以从墙壁、地板和天花板后面看到一个场景,以提供相对大的背景和小的遮挡。
- 我们根据已知的虚拟视图的摄像机参数将像素预测聚合到三维表面上,这样就不会在咬合轮廓上遇到语义标签的“溢出”。
- 在训练和推理过程中的虚拟视图可以模拟多尺度的训练和测试,避免二维cnn的尺度内方差问题。在培训和测试期间,我们可以生成任意数量的虚拟视图。在训练期间,由于数据的增加,更多的虚拟视图提供了健壮性。在测试期间,由于投票冗余,更多的视图提供了健壮性。
- 我们的多视点融合方法中的二维分割模型可以受益于大型图像预处理数据,如ImageNet和COCO,这些数据对于纯三维卷积方法是不可用的。
方法
总体流程
Training stage.
在训练阶段,首先为每个3D场景选择虚拟视图,然后为每个虚拟视图选择摄影机内在,摄影机外部,要渲染的通道以及渲染参数(例如,深度范围,背面剔除).
然后,通过为所选通道和groudtruth语义标签渲染所选虚拟视图来生成训练数据。
使用渲染的训练数据训练2D语义分割模型,并在推理阶段使用该模型。
Inference stage.
在推理阶段,使用与训练阶段类似的方法来选择并渲染虚拟视图,但是没有groudtruth语义标签。
使用训练好的模型在渲染的虚拟视图上进行2D语义分割,将2D语义特征投影到3D,然后通过融合多个投影的2D语义特征来导出3D中的语义类别。
虚拟视图选择
Camera intrinsics.
使用针孔摄像机模型,提高了FOV,得到的二维图像更大,提供了更大的上下文信息。
Camera extrinsics.
使用以下四种策略选择相机外参
- 均匀采样:
均匀采样相机外部,以生成许多新颖的视图,而与3D场景的特定结构无关。
具体,使用3D场景顶部均匀采样位置的自顶向下视图,以及从场景中心看去但均匀采样位置的视图。 - 尺度不变采样:
由于2D卷积神经网络通常不是尺度不变的,因此如果视图的尺度与3D场景不匹配,则模型性能可能会受到影响。
为了克服此限制,针对3D场景中的片段以一定比例尺对视图进行采样。
具体来说,对3D场景进行了过度分割,对于每个片段,都将相机定位为通过沿法线方向拉回到一定范围的距离来观看片段。
进行深度检查以避免前景物体的遮挡。如果在渲染阶段禁用了背面剔除,将进行光线跟踪并删除被背面遮挡的所有视图。
3D场景的过度分割是不受监督的,并且不使用地面真实语义标签,因此尺度不变采样可以应用于训练和推理阶段。 - 类平衡采样:
类平衡已被广泛用作2D语义分段的数据增强方法。
通过选择查看代表性不足的语义类别的网格段的视图来进行类平衡,类似于尺度不变采样方法。
注意,这种采样方法仅适用于ground truth语义标签可用的训练阶段。 - Original views sampling:
从原始摄影机视图中进行采样,因为它们代表了人工如何在具有实际物理约束的真实3D场景中选择摄影机视图。
此外,3D场景是从原始视图重建的,因此包含它们可以确保覆盖拐角情况,否则这些情况很难作为随机虚拟视图。Channels for rendering.
渲染了以下通道:RGB color、normal、规范化全局XYZ坐标。额外的通道允许我们超越现有RGB-D传感器的限制。图5显示了虚拟视图渲染的通道。
Rendering parameters.
在渲染视图时可打开背景剔除,这样相机视图不会被遮挡,例如一个场景中,我们既可以选择外部视图,也可以选择内部视图。如图6所示。
Training vs. inference stage.
我们希望在训练和推理阶段使用类似的视图选择方法,以避免产生领域差距。虽然推理成本在现实世界的应用中可能很重要,但在本文中,考虑离线3D分割任务且不在任何一个阶段优化计算成本,所以论文在任何一个阶段使用任意多的虚拟视图。
Multiview Fusion
2D semantic segmentation model
用渲染的虚拟视图作为训练数据,训练一个2D语义分割模型。使用xception 65特征提取器和DeeplabV3+ 解码器。
从在ImageNet上训练的预先训练的分类模型检查点初始化模型。当使用附加输入通道(如正常图像和坐标图像)训练模型时,通过将权重平铺在附加通道上并在每个空间位置对其进行归一化来修改预训练检查点的第一层,使得沿着通道维度的权重总和保持不变。
3D fusion of 2D semantic features
在推理过程中,在虚拟视图上运行2D语义分割模型,并获得图像特征(例如,每个像素的一元概率)。为了将2D图像特征投影到3D,使用以下方法:
- 在虚拟视图上渲染深度通道;
- 对于每个3D点,将其投影回每个虚拟视图,并且仅当像素的深度与点到相机的距离匹配时,才累积投影像素的图像特征。
- 与从每个像素投射光线以找到要聚集的3D点的替代方法相比,该方法实现了更好的计算效率。
- 首先,场景中3D点的数量远小于场景的所有渲染图像中的像素总数。
- 其次,使用深度检查投影3D点比涉及光线投射的操作更快。


Experiments
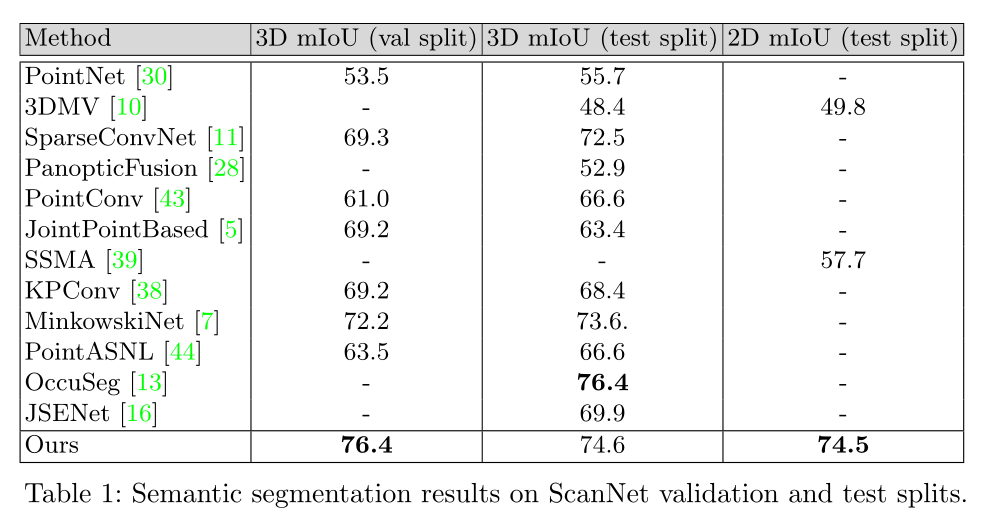
Scannet
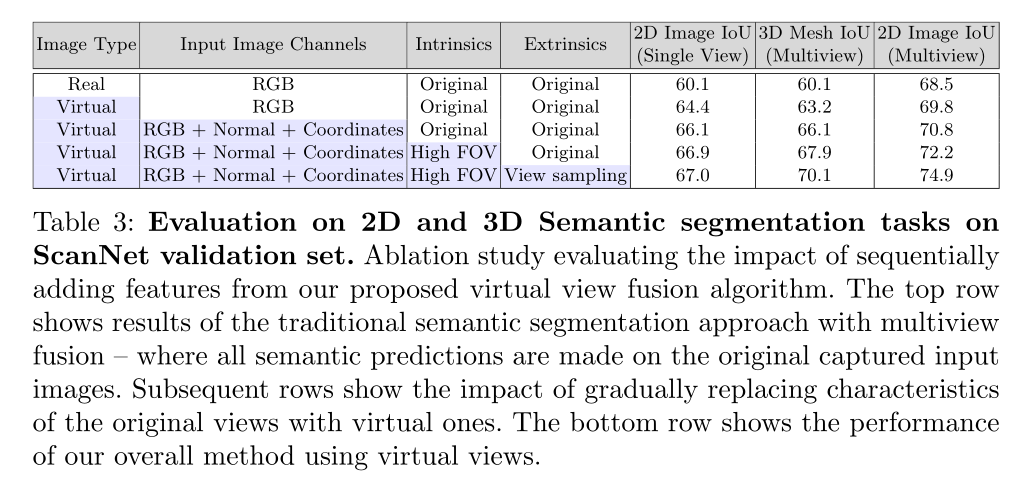

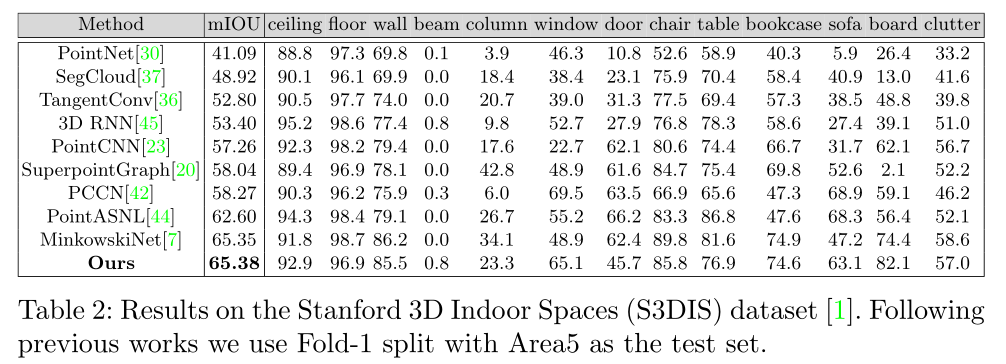
S3DIS
Effect of Training Set Size and number of views at Inference
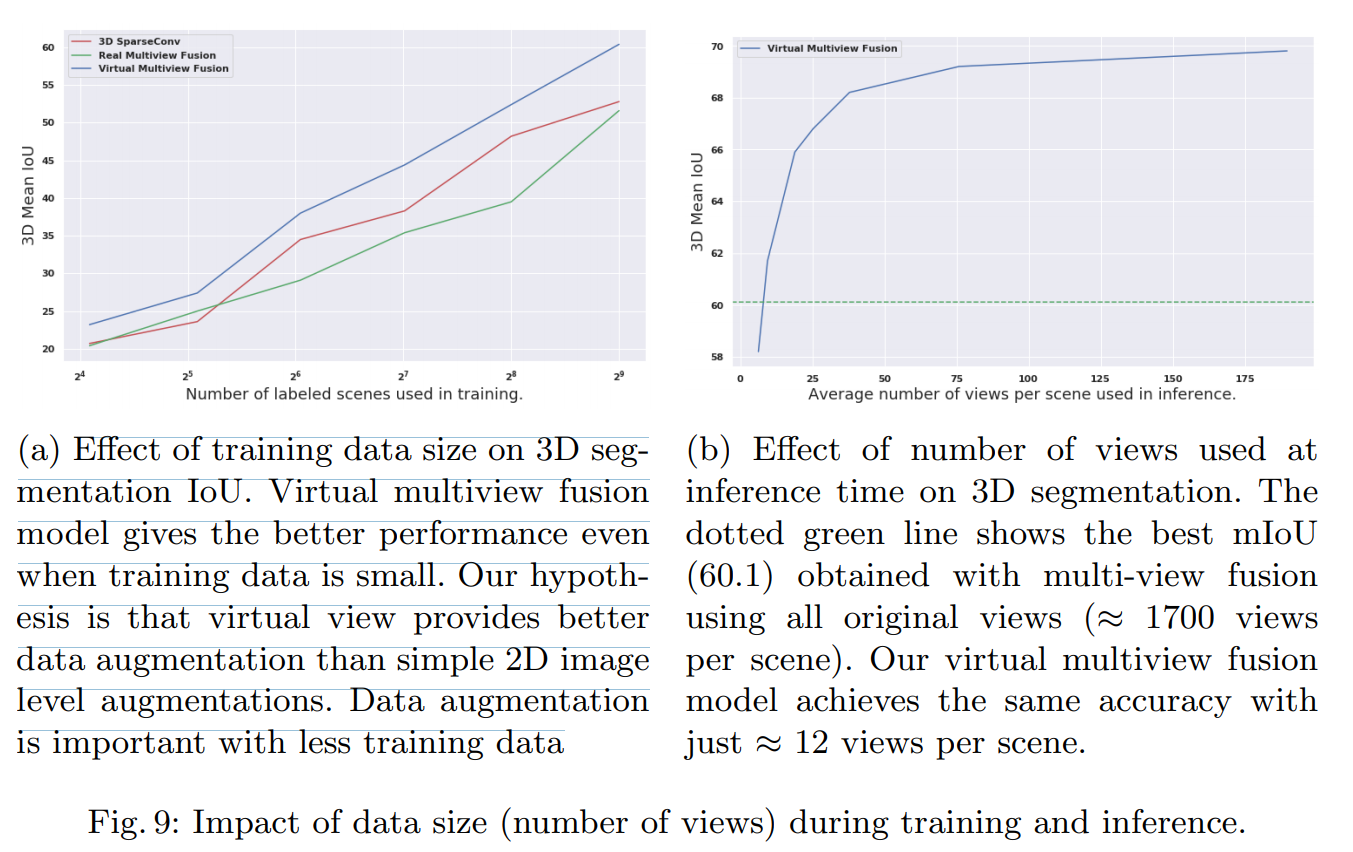
结论
本文提出了一种虚拟多视角融合的纹理meshes三维语义分割方法。这种方法引入了几个显著提高标签性能的新思想:带有附加通道的虚拟视图、背面剔除、宽视野、多尺度感知视图采样。因此,它克服了困扰大多数以前多视角融合方法的2D-3D错位、遮挡、窄视角和尺度不变性问题。
本文得出的令人惊讶的结论是,多视图融合算法是3D纹理网格语义分割的3D卷积的可行替代方案。虽然这项任务的早期工作考虑了多视图融合,但近年来,通用方法已被放弃,取而代之的是点云的3D卷积和稀疏体素网格。本文表明,仔细选择和渲染虚拟视图的简单方法使得多视图融合能够优于几乎所有最近的3D卷积网络。