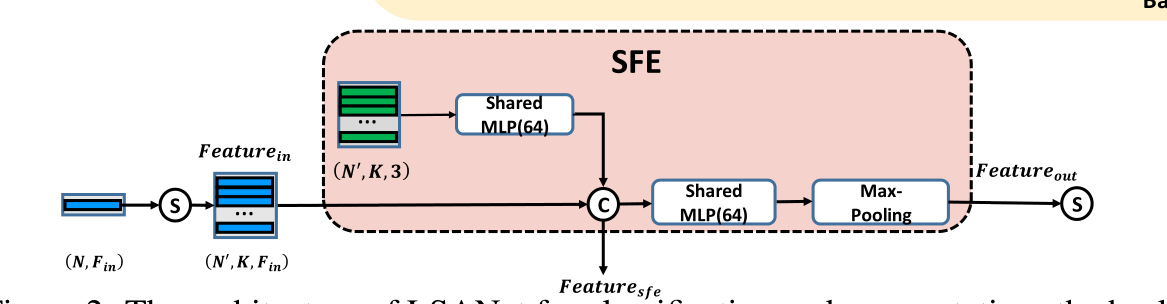
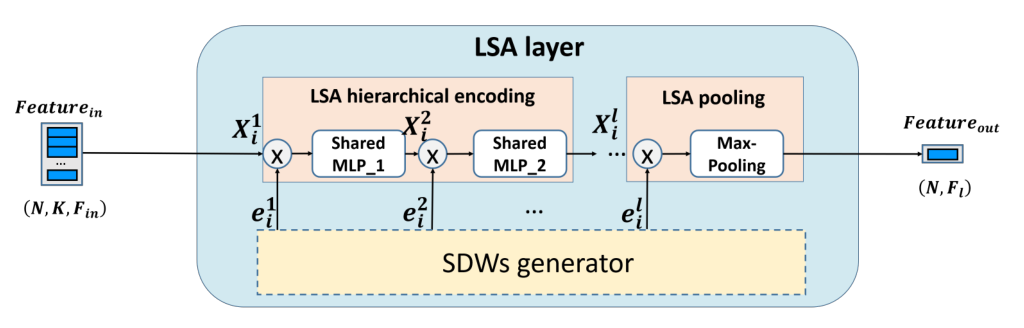
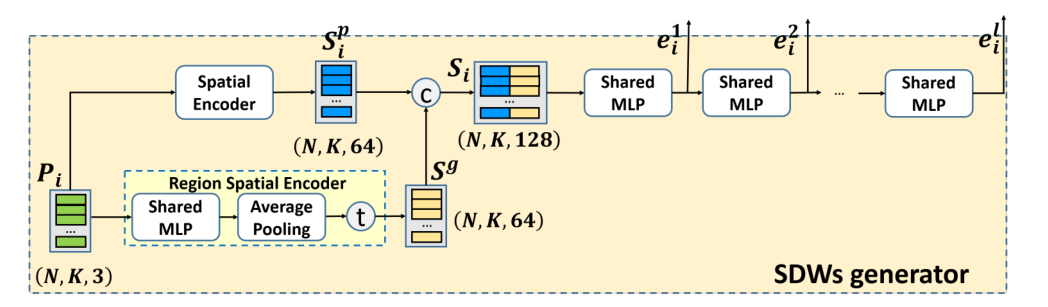
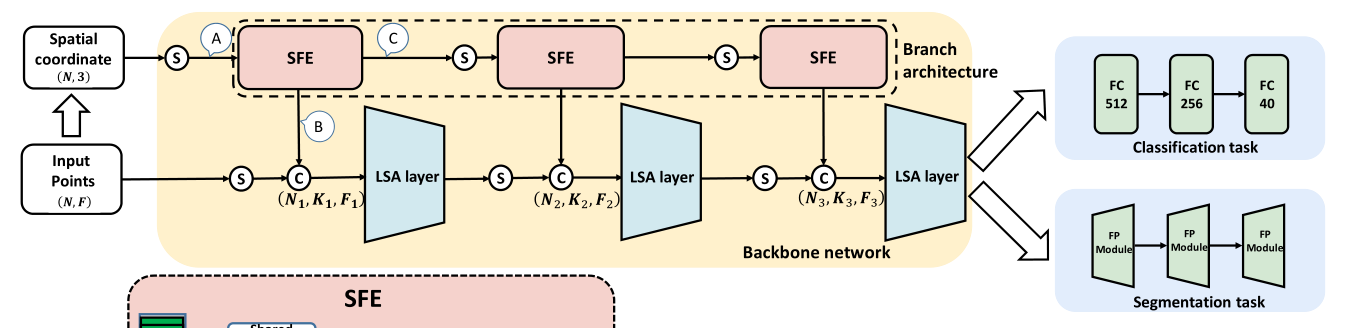
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| def LSA_layer(xyz, points, npoint, radius, nsample, mlp, mlp2, group_all, is_training, bn_decay,
scope, xyz_feature=None, bn=True, pooling='max', knn=False, use_xyz=True, use_nchw=False,
end=False):
''' LSA layer
Input:
xyz: (batch_size, ndataset, 3) TF tensor BxNx3的点的xyz信息
points: (batch_size, ndataset, channel) TF tensor BxNxC的点的特征信息,如果为空则用xyz
npoint: int32 -- #points sampled in farthest point sampling 点的数量
radius: float32 -- search radius in local region 采样分组的半径
nsample: int32 -- how many points in each local region 采样点的数量
mlp: list of int32 -- output size for MLP on each point 每个点在mlp中输出的通道大小
mlp2: list of int32 -- output size for MLP on each region 每个局部区域在mlp中输出的通道大小
group_all: bool -- group all points into one PC if set true, OVERRIDE
npoint, radius and nsample settings
is_training: bool -- whether train this LSA layer
bn_decay: float32 -- batch norm decay
scope: scope in tensorflow
xyz_feature: float32 -- feature from SFE 即是Feature_out
use_xyz: bool, if True concat XYZ with local point features, otherwise just use point features
use_nchw: bool, if True, use NCHW data format for conv2d, which is usually faster than NHWC format
Return:
new_xyz: (batch_size, npoint, 3) TF tensor 新的xyz
new_points: (batch_size, npoint, mlp[-1] or mlp2[-1]) TF tensor 新的points
idx: (batch_size, npoint, nsample) int32 -- indices for local regions 局部点的索引
xyz_feature: LSA layer 的Feature_out
'''
data_format = 'NCHW' if use_nchw else 'NHWC'
with tf.variable_scope(scope) as sc:
if group_all:
nsample = xyz.get_shape()[1].value
new_xyz, new_points, idx, output_feature, xyz_feature, grouped_xyz = sample_and_group_all(xyz, points, bn, is_training, bn_decay, mlp2, use_xyz, xyz_feature, end, use_edge_feature=True)
else:
new_xyz, new_points, idx, output_feature, xyz_feature, grouped_xyz = sample_and_group(npoint, radius, nsample, xyz, points, bn, is_training, bn_decay, mlp2, knn, use_xyz, xyz_feature, end, use_edge_feature=True)
new_points = tf.concat([new_points, output_feature], axis=-1)
channel = new_points.get_shape()[-1].value
attention_xyz_1 = tf_util.conv2d(grouped_xyz, 64, [1, 1],
padding='VALID', stride=[1, 1],
bn=bn, is_training=is_training,
scope='xyz_attention_1', bn_decay=bn_decay,
data_format=data_format)
attention_xyz_2 = tf_util.conv2d(grouped_xyz, 64, [1, 1],
padding='VALID', stride=[1, 1],
bn=bn, is_training=is_training,
scope='xyz_attention_2', bn_decay=bn_decay,
data_format=data_format)
attention_xyz_2 = tf.reduce_mean(attention_xyz_2, axis=[2], keep_dims=True, name='meanpool')
attention_xyz_2 = tf.tile(attention_xyz_2, [1, 1, nsample, 1])
attention_xyz = tf.concat([attention_xyz_1, attention_xyz_2], axis=-1)
for i, num_out_channel in enumerate(mlp):
new_points = tf_util.conv2d(new_points, num_out_channel, [1, 1],
padding='VALID', stride=[1, 1],
bn=bn, is_training=is_training,
scope='conv%d' % (i), bn_decay=bn_decay,
data_format=data_format)
attention_xyz = tf_util.conv2d(attention_xyz, num_out_channel, [1, 1],
padding='VALID', stride=[1, 1],
bn=bn, is_training=is_training,
scope='xyz_attention%d' % (i), bn_decay=bn_decay,
data_format=data_format, activation_fn=tf.sigmoid)
new_points = tf.multiply(new_points, attention_xyz)
new_points = tf.reduce_max(new_points, axis=[2], keep_dims=True, name='maxpool2')
new_points = tf.squeeze(new_points, [2])
return new_xyz, new_points, idx, xyz_feature
|